Un nuevo marco de ataque tiene como objetivo inferir las pulsaciones de teclas escritas por un usuario objetivo en el extremo opuesto de una llamada de videoconferencia simplemente aprovechando la transmisión de video para correlacionar los movimientos corporales observables con el texto que se está escribiendo.
La investigación fue realizada por Mohd Sabra y Murtuza Jadliwala de la Universidad de Texas en San Antonio y Anindya Maiti de la Universidad de Oklahoma, quienes dicen que el ataque puede extenderse más allá de las transmisiones de video en vivo a las que se transmiten en YouTube y Twitch siempre que un El campo de visión de la cámara web captura los movimientos visibles de la parte superior del cuerpo del usuario objetivo.
«Con la reciente ubicuidad del hardware de captura de video integrado en muchos productos electrónicos de consumo, como teléfonos inteligentes, tabletas y computadoras portátiles, la amenaza de fuga de información a través del canal visual[s] ha amplificado «, dijeron los investigadores.» El objetivo del adversario es utilizar los movimientos observables de la parte superior del cuerpo en todos los cuadros grabados para inferir el texto privado escrito por el objetivo «.
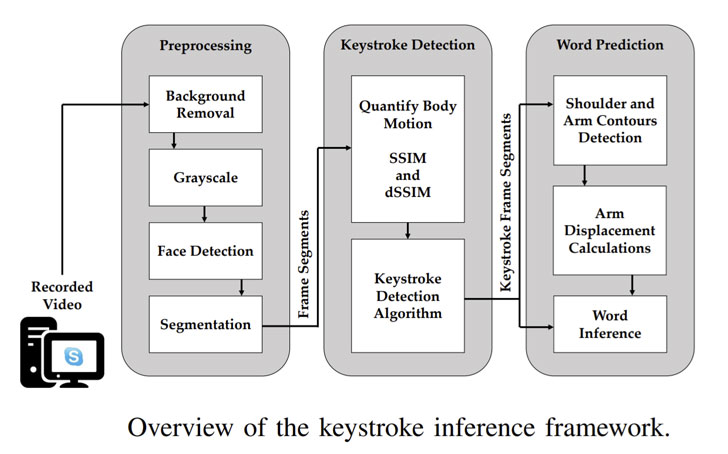
Para lograr esto, el video grabado se alimenta a un marco de inferencia de pulsaciones de teclas basado en video que pasa por tres etapas:
- Preprocesamiento, donde se elimina el fondo, el video se convierte a escala de grises, seguido de la segmentación de las regiones del brazo izquierdo y derecho con respecto a la cara del individuo detectada a través de un modelo denominado FaceBoxes
- Detección de pulsaciones de teclas, que recupera los cuadros de brazos segmentados para calcular la medida del índice de similitud estructural (SSIM) con el objetivo de cuantificar los movimientos del cuerpo entre cuadros consecutivos en cada uno de los segmentos de video del lado izquierdo y derecho e identificar cuadros potenciales donde ocurrieron las pulsaciones de teclas
- Predicción de palabras, donde los segmentos de cuadro de pulsación de tecla se utilizan para detectar características de movimiento antes y después de cada pulsación de tecla detectada, utilizándolos para inferir palabras específicas utilizando un algoritmo de predicción basado en diccionario
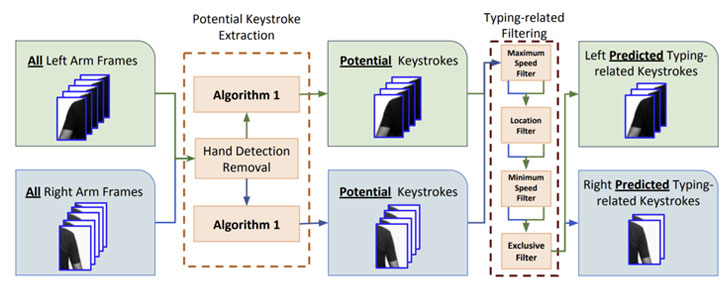
En otras palabras, del conjunto de pulsaciones de teclas detectadas, las palabras se infieren haciendo uso del número de pulsaciones de teclas detectadas para una palabra, así como la magnitud y dirección del desplazamiento del brazo que se produce entre pulsaciones consecutivas de la palabra.
Este desplazamiento se mide usando una técnica de visión por computadora llamada Flujo óptico disperso que se usa para rastrear los movimientos de los hombros y los brazos a través de marcos cronológicos de pulsaciones de teclas.
Además, también se representa una plantilla para «direcciones entre pulsaciones de teclas en el teclado QWERTY estándar» para indicar las «direcciones ideales que debe seguir la mano de un tipeador» usando una combinación de manos izquierda y derecha.
El algoritmo de predicción de palabras, entonces, busca las palabras más probables que coincidan con el orden y el número de pulsaciones de teclas con la mano izquierda y derecha y la dirección de los desplazamientos de los brazos con las direcciones entre pulsaciones de teclas de la plantilla.
Los investigadores dijeron que probaron el marco con 20 participantes (9 mujeres y 11 hombres) en un escenario controlado, empleando una combinación de métodos de búsqueda y picoteo y mecanografía táctil, además de probar el algoritmo de inferencia en diferentes entornos, modelos de cámaras web, ropa (particularmente el diseño de la funda), teclados e incluso varios software de videollamadas como Zoom, Hangouts y Skype.
Los hallazgos mostraron que los que escriben a máquina y los que usan ropa sin mangas eran más susceptibles a los ataques de inferencia de palabras, al igual que los usuarios de cámaras web de Logitech, lo que resultó en una mejor recuperación de palabras que aquellos que usaron cámaras web externas de Anivia.
Las pruebas se repitieron nuevamente con 10 participantes más (3 mujeres y 7 hombres), esta vez en una configuración casera experimental, infiriendo con éxito el 91,1 % de los nombres de usuario, el 95,6 % de las direcciones de correo electrónico y el 66,7 % de los sitios web escritos por los participantes. pero solo el 18,9% de las contraseñas y el 21,1% de las palabras en inglés escritas por ellos.
«Una de las razones por las que nuestra precisión es peor que la configuración In-Lab es porque la clasificación del diccionario de referencia se basa en la frecuencia de uso de palabras en oraciones en inglés, no en palabras aleatorias producidas por personas», Sabra, Maiti y Jadliwala Nota.
Al afirmar que el desenfoque, la pixelación y la omisión de cuadros pueden ser una táctica de mitigación efectiva, los investigadores dijeron que los datos de video se pueden combinar con datos de audio de la llamada para mejorar aún más la detección de pulsaciones de teclas.
“Debido a los recientes acontecimientos mundiales, las videollamadas se han convertido en la nueva norma para la comunicación remota tanto personal como profesional”, destacan los investigadores. «Sin embargo, si un participante en una videollamada no tiene cuidado, él / ella puede revelar su información privada a otros en la llamada. Nuestras precisiones de inferencia de pulsaciones de teclas relativamente altas en entornos realistas y que ocurren comúnmente resaltan la necesidad de conciencia y contramedidas contra este tipo de ataques».
Se espera que los hallazgos se presenten más tarde hoy en el Simposio de seguridad de redes y sistemas distribuidos (NDSS).